From frustration to celebration - The magic that comes when GraphQL and TypeScript work together

As a seasoned frontend engineer, you’ve likely encountered the recurring nightmare of API specifications changing without notice. The aftermath? Your once-flawless application in production now stands broken. Blame it on miscommunication or inadequate planning from the team, the reality remains — you’re left grappling with prolonged debugging sessions and sleepless nights.
On the other hand, backend developers often feel uncertain about modifying APIs, fearing potential disruptions to client applications. This anxiety can result in hesitancy, slowing down essential updates and affecting the overall development process.
In my journey as a tech lead, this scenario became an all-too-familiar tale, causing endless frustration and countless hours spent deciphering API alterations made or to be made. That changed when I discovered the magic that comes when GraphQL and TypeScript work together.
Tackling Common Challenges Head-On
Let’s go over some common challenges our team encountered when it came to API integration and maintenance:
Challenge 1: Guarding Against Field Removal
Imagine this scenario: during our journey, there was a moment when we intentionally removed a field from the schema. The big question was, how do you figure out which part of the client uses this field and what happens if you make this change? Text search is one way when developer is in the loop, but it’s not effective when you aim to automate the process.
Challenge 2: Safeguarding Against Changes in a Field
In a different scenario, we learned that validation shouldn’t only focus on removed fields; even changes to existing fields need a closer look.
For instance, when we chose to make the ‘author’ field in the ‘Post’ type nullable in the schema (for whatever reason), it led to an unexpected error in the frontend at runtime. This taught us the importance of being extra cautious to shield the frontend code from possible runtime errors.
What if the IDE could raise an error similar to the one below whenever there is a change in the API?
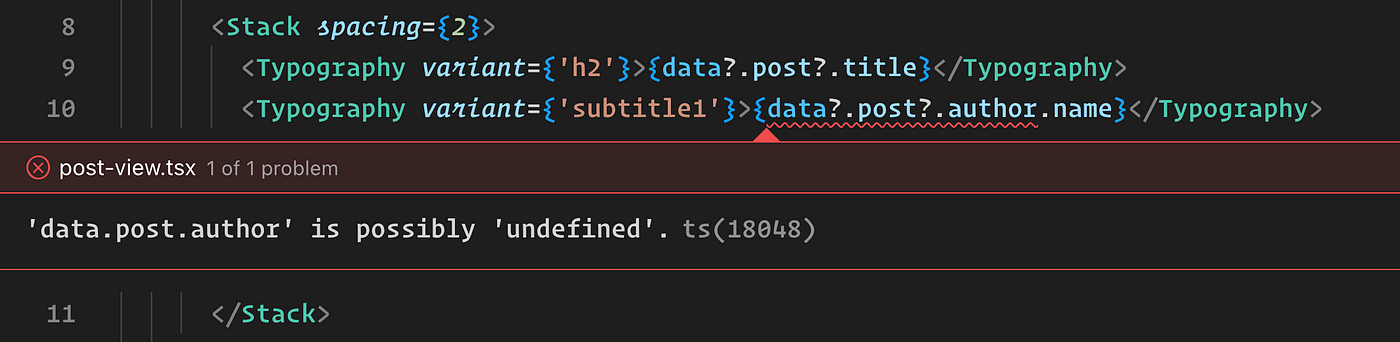
Safeguarding Against Changes in Type and Nullability
Challenge 3: Avoiding Pitfalls with Unfetched Fields
This scenario often goes unnoticed. Using a field from the original schema that’s not part of the GraphQL query should also ring alarms, as it’s the easiest way to cause issues in the frontend. We discovered it the hard way that generating typings for the entire schema works against this situation. So, the question arose: how can we ensure that only the fields we fetched are actually used by the client?
What if the IDE could raise an error similar to the one below whenever there is a change in the API?
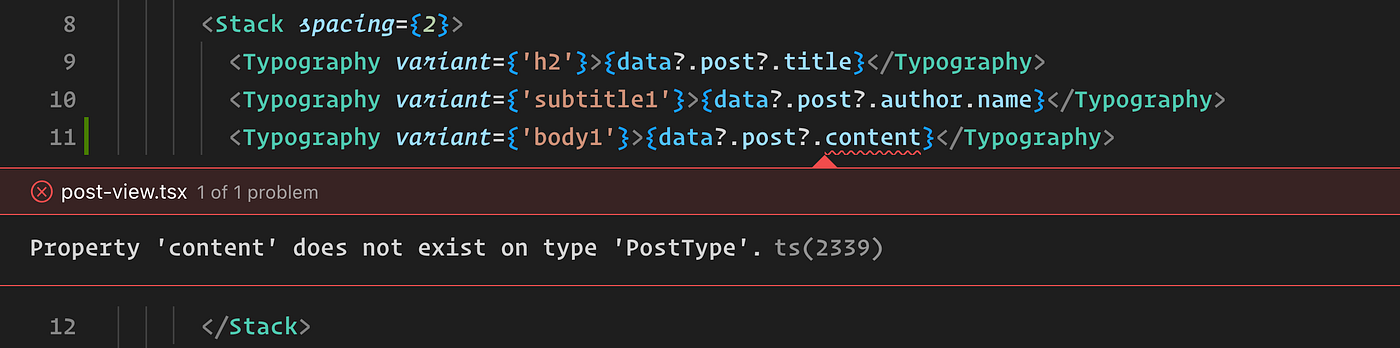
Avoiding Pitfalls with Unfetched Fields
Challenge 4: Keeping up with Input Changes
I’m willing to bet that if you’ve ever attempted to write a GraphQL query, you may have accidentally messed up the input type at least once. Our team faced this issue too, and it occurred quite frequently. The question arose: How can we generate and manage inputs from the schema without burdening the frontend developer? How can we ensure the name, type, and nullability stay in sync?
It was clear. The basic setup wasn’t enough.
As with most projects, we made sure to set up ESLint and TypeScript properly in our workspace. This ensured that our code received a check every time we made a small tweak. But that wasn’t sufficient. For the checks to be truly effective, the frontend code especially the code that interacts with the API should be strongly typed.
It’s time to answer the big question: how did we change the developer experience from frustration to celebration?
Our approach was three-fold
We revamped the development process with three simple moves that made a big impact. This three-fold approach not only enhanced collaboration but also significantly reduced the burden on our development team.
Step 1: One Home for All: We created a single home for both frontend and backend code — a mono-repo. No more juggling between repositories! This made sharing GraphQL schema easy. The backend team automated the schema updates, keeping expectation from both sides in sync.
Step 2: Tailored Typing for GraphQL: Instead of using generic typings from the entire schema, we made specific TypeScript typings for each query and mutation. This meant more accurate typing for each interaction with the API. This idea also aligns with GraphQL’s principle of fetching only what is necessary to optimally support your UI feature. We used a handy tool for quick and accurate typing generation.
Step 3: Enforcing Type-Checking Everywhere: We applied these typings consistently across our frontend. This wasn’t just a formality — it gave us a strong type-checking system. No more “as any” shortcuts! This ensured that our code stayed reliable and API-compatible. Additionally, we automated type-checking as part of PR review for efficiency.
Let’s break down each step.
Step 1: One Home For All
We created a single home for both frontend and backend code — a mono-repo. This made sharing GraphQL schema easy. In case of a monorepo, here is the typical file structure for my projects.
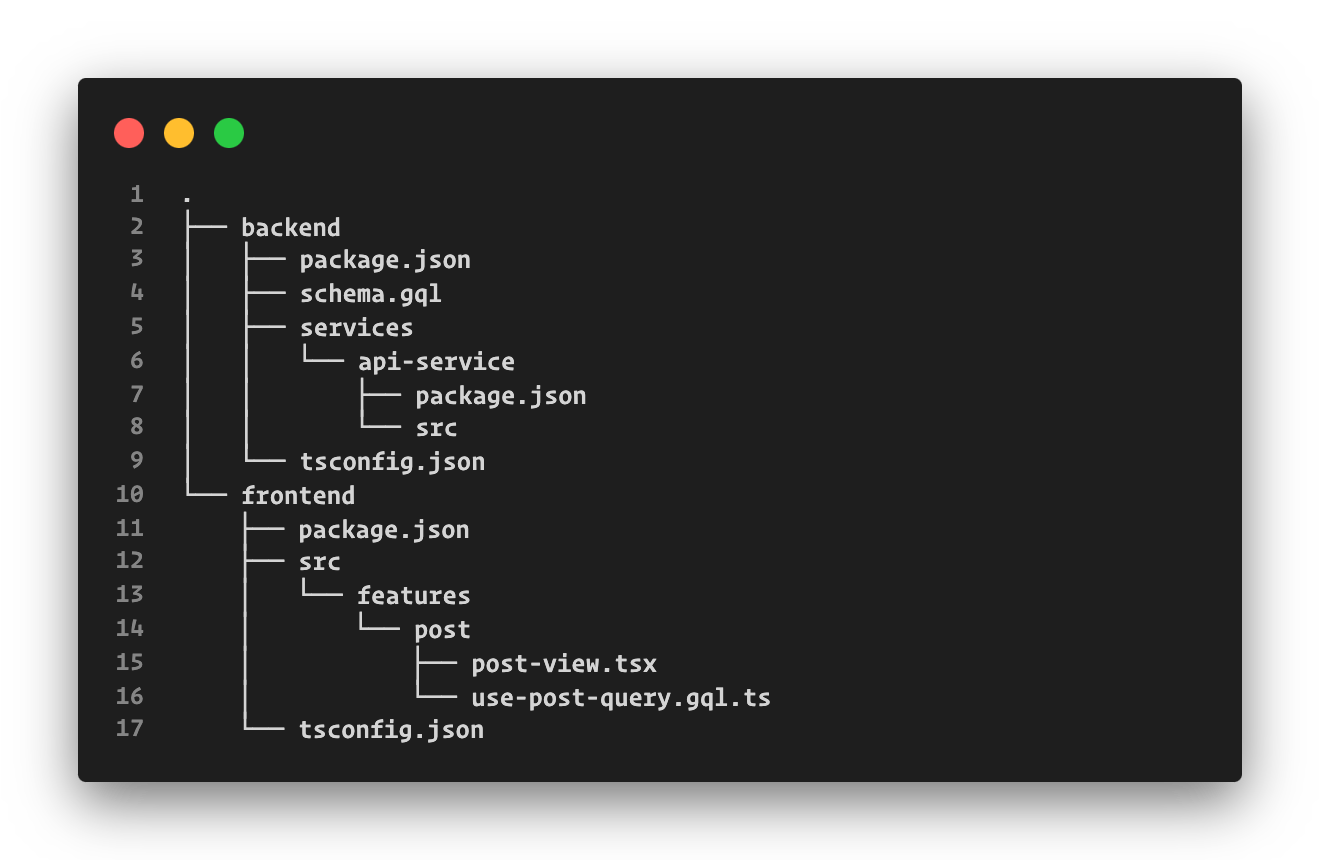
Typical project structure
The crucial element in this structure are the schema.gql (at line 4) file which outlines the API structure, and the React hook use-post-query.gql.ts(at line 16) that leverage GraphQL APIs.
Before we move forward, I’d like to address a point that often sparks discussion. Why did we choose a mono-repo?
While the entire setup can work without a mono-repo, we noticed a significant improvement in efficiency when we implemented one.
Here’s why:
By consolidating both frontend and backend code in a single repository, we were able to employ the same set of tools to automatically verify the code against changes in schema.gql. This simplified approach has notably enhanced our workflow. Now, both frontend and backend engineers can easily discern the impact of their modifications, all while utilizing the same tools under a same PR branch.
Let’s explore the schema:
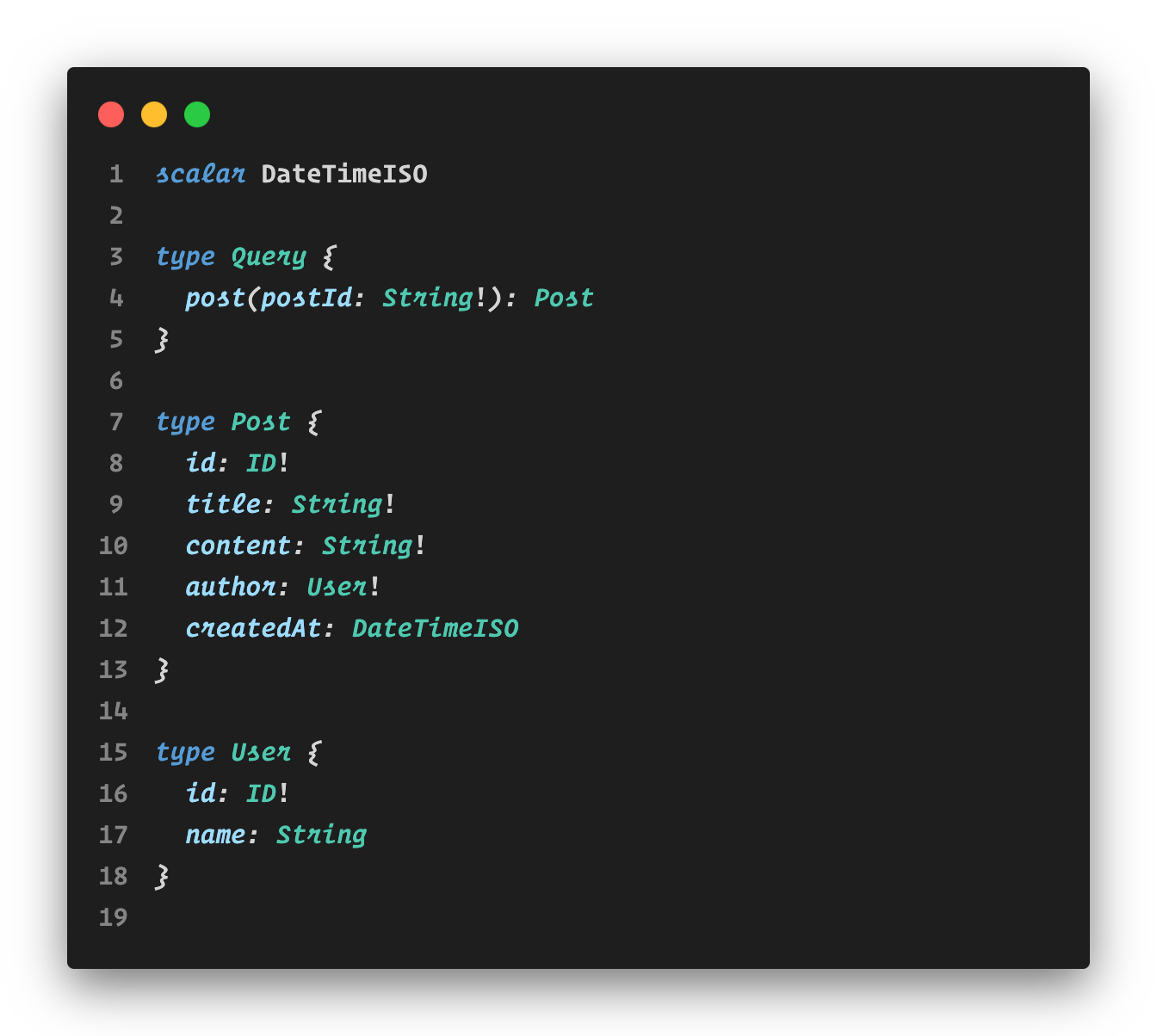
Step 2: Tailored Typing for GraphQL
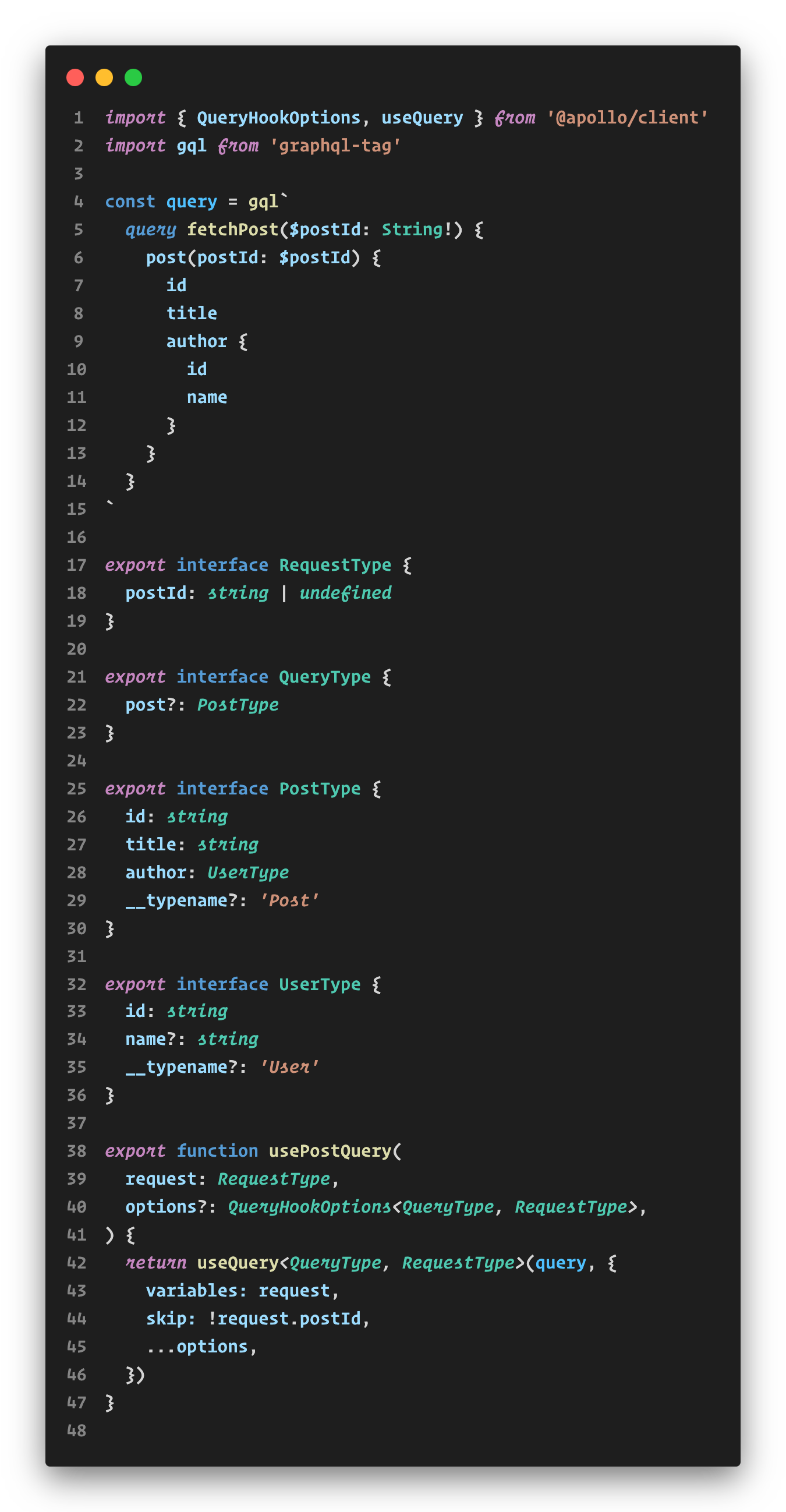
In our next step, we took each API interaction and put it into a file with the extension “.gql.ts”. These files contained three key elements:
- GraphQL query or mutation to be used
- TypeScript interfaces and enums defining both the request and response
- A strongly typed React Hook that internally utilizes useQuery or useMutation hooks from the library @apollo/client (opens in a new tab).
See that tool in action:
Here’s how it works in two simple steps:
Step 1: Write a basic form of a query/mutation — Start by writing a basic form of a query/mutation in a file with a .gql.ts extension. Hooks are intentionally given the extension .gql.ts, a choice that aids us in automating the generation of typings. More on that soon.
Step 2: Just Save the file — Behind the scenes, we automated it to execute the following command.
npx gql-hook-codegen generatesThis process simultaneously creates both typings and a strongly-typed React hook. It achieves this based on two key factors: firstly, the schema, and secondly, the fields used by the query or mutation in this file. This establishes a robust foundation for static type checking.
Furthermore, if you were to use the query (like “post” in the example below) in a different section of your frontend application with distinct field requirements, it would have its own set of typings, differing from the ones defined here.
Two types of automation played a tremendous role in tying everything together. The first one aided in managing our code workspace, while the second one ensured the validation of each PR before it gets merged.
Automate on Save for Effortless Type Generation
If you’re working with TypeScript projects in the VSCode editor (which is highly recommended 🙂), you can automate the regeneration of typings when modifying a query or mutation. That’s what we did through these steps:
- Install the saveAndRun (opens in a new tab) extension from Visual Studio Marketplace
- Update
frontend/.vscode/settings.jsonas illustrated below:
{
"saveAndRun": {
"commands": [
{
"match": ".gql.ts",
"cmd": "npx gql-hook-codegen generate --pattern ${file}",
"useShortcut": false,
"silent": false
}
]
}
}Now you know why hooks are intentionally given the extension .gql.ts.
Automated PR Validation
Even if you forget to regenerate hooks on save which happened to us frequently especially when changes occurred only in the schema.gql file, this second step can be a lifesaver. We automated the hook generation through GitHub Actions.
Here’s how we implemented it in 4 straightforward steps:
- Generate schema
- Regenerate hooks using the using the tool gql-hook-codegen (opens in a new tab)
- Perform linting and formatting
- Commit any changes in the code back to the branch
name: Lint
on: pull_request
jobs:
lint-backend:
name: Lint backend
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@master
- uses: actions/setup-node@v1
with:
node-version: '18.x'
- run: yarn install
working-directory: ./backend
- run: yarn install
working-directory: ./frontend
- run: yarn generate:schema
working-directory: ./backend
- run: npx gql-hook-codegen generate
working-directory: ./frontend
- run: yarn run lint
working-directory: ./frontend
- uses: EndBug/add-and-commit@v7
with:
author_name: github-actions-gm
author_email: bot+github-actions-gm@users.noreply.github.com
message: 'refactor: Regenerate GraphQL hooks and address code style issues.'
push: '--set-upstream origin'Thanks to these two automations, our development process has become streamlined. Every change made by both frontend and backend engineers now undergoes strict validation and confirmation. This has significantly helped us mitigate all the challenges we discussed earlier.
A Final Note
I talked about how using GraphQL with TypeScript can improve your full-stack development, especially with React. But remember, this concept applies to any frontend, not just React.
For example, our CLI clients utilize the same GraphQL APIs. The only difference is that it doesn’t depend on @apollo/client (opens in a new tab) but uses a straightforward fetch library like node-fetch (opens in a new tab). We were able to apply the same tool to achieve all these great things with a simple change.
npx gql-hook-codgen generate --library @yourproject/use-query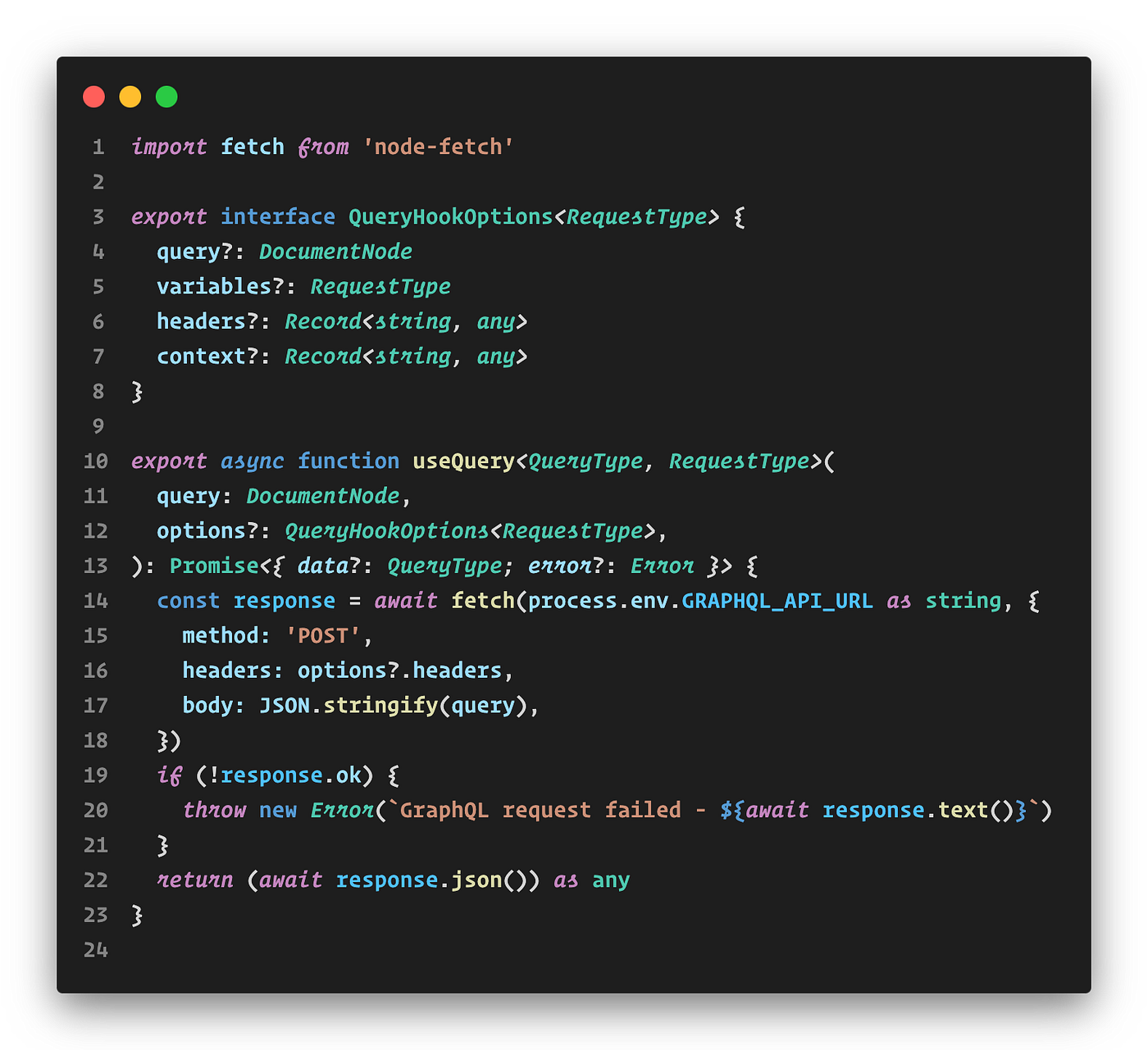
Let me know how this idea was useful for your own client library.
GraphQL provides substantial advantages when it comes to statically verifying client applications. Its robust type system ensures type safety and early error detection, ultimately enhancing the reliability of client applications. If you aim to build robust and dependable client applications, consider integrating GraphQL and TypeScript into your tech stack.
Check out the useful tool gql-hook-codgen (opens in a new tab) on my Github Repository (opens in a new tab).
If you found this article helpful, please express your feedback through a like or a comment. Additionally, consider subscribing to my newsletter.
Thank you for your time.
Subscribe to Newsletter
Please provide a valid email address.